
.svg)
AI Engineering Ops Platform optimizing teams that are building the future.

Popular articles
AI coding agents are already inside your delivery pipeline. They are drafting code, calling tools, and taking ideas all the way to production. On paper, this should feel like magic.
In practice, it often feels like a black box.
You do not really know how good the code is until a human has spent just as much time reviewing it as they would have spent writing it in the first place. Leaders get dashboards about "AI adoption," but very little proof that AI is actually speeding up delivery. Meanwhile, security teams see a growing tangle of prompts, tools, and plugins they never approved.
This is the AI era's version of "shadow IT": shadow AI.
According to Harness's State of AI-Native Application Security 2025 report, nearly two-thirds of organizations have seen exploits involving vulnerable LLM-generated code, and three-quarters have experienced prompt-injection incidents in production environments. Shadow AI is already in prod.[1]
It is now clear that you cannot ship AI-coded software safely or quickly without observability that is purpose-built for coding agents.
This post walks through the problem, the signals you need to capture, and a practical closed-loop approach to go from "black box" to "observe, govern, and optimize."
The Black Box Problem
Imagine a typical AI-assisted change.
A developer opens a PR. Most of the diff was drafted by a coding agent. Somewhere in the background, that agent has called multiple models, tools, and MCP servers. It has rewritten the same function a few times. It has pulled in context from different files and maybe even external systems.
What you see is just the final patch.
Behind that patch are several problems that traditional tooling does not surface.
Invisible prompts and tools
Most of the important context lives outside your normal logs. Prompts, tool calls, model parameters, and external MCP servers are not visible in your standard CI or APM views. When something breaks, you cannot easily answer: "What exactly did the agent do, and why?"
Without lineage, you cannot reliably reproduce failures or investigate incidents. You only see the symptom, never the full story.
Variance that kills flow
Every team experiments with different flows: different agents, different plugins, different ways of prompting. Some developers rely on agents heavily. Others barely touch them. Retries stack up as developers keep nudging the agent to "try again" until the code looks right.
Time-to-merge quietly stretches out.
People start saying, "AI feels slower," but no one can point to exactly where the time is going: retries, rework, reviews, or rollbacks.
Security and leakage risk
At the same time, your attack surface is shifting left.
Data leakage now happens during the construction phase, not just at runtime. Agents may call external MCP servers or tools that were never sanctioned by IT. Sensitive data can leave your environment before a single deployment.
Traditional scanners were built for static code, not model-driven behavior. They struggle to understand prompts, tool calls, and the context that led to a dangerous change.
No ROI proof
Finally, leaders are being asked to bet big on AI without real proof.
Did AI coding actually improve velocity for this team? Did defect rates go down or up? Are reviewers spending less time on PRs, or more?
Without structured telemetry, you cannot walk into a board meeting and say, "Here is our time-to-merge delta and defect reduction attributable to AI-coded changes." You are left with anecdotes and optimism.
What We Really Need to See from Coding Agents
Generic tracing is not enough. You do not just need more logs. You need code-aware, high-cardinality telemetry that tells the story of how code was produced.
At a minimum, that includes:
- Prompt and tool-call lineage per PR or commit. For any change, you should be able to see who or what called which model, with which parameters, and which tool steps were executed. This is your ground truth for incident investigation and reproducibility.
- Throughput and flow metrics. How long does each AI-assisted workflow run? How much time passes from first AI-generated diff to merge? How much of review time is spent on rework from AI suggestions? These metrics tell you whether agents are actually speeding you up or quietly slowing you down.
- Drift signals. When prompts, tools, or flows drift from a last known-good baseline, you should know. If a new tool suddenly appears in a critical path, that should be visible, not a surprise buried in a log line.
- Security signals. Injection attempts, leakage patterns, unapproved tool usage, and unexpected data flows should be first-class signals, not side effects. You want to catch these during construction, not after an incident report.
- Eval outcomes. Automated evaluations on AI-generated diffs-correctness checks, hallucination detection, schema and contract enforcement, and drift tests-should feed directly into how you trust and use specific agents or models.
Without this level of observability, you are always reacting after the fact.
Why Conventional Monitoring Fails AI Coding Work
If you squint, it is tempting to treat AI coding as "just another service" and point your existing monitoring stack at it. That rarely works.
Traditional APM, CI, and logging tools were built for deterministic systems and static code paths. AI coding is neither.
Here is what changes:
Behavior shifts daily
Models update. Prompts evolve. Plugin sets change. New skills or tools get added to an agent. None of this requires a code deployment.
Your system's behavior can change tomorrow morning even if no one merges a single PR. Existing dashboards, which assume code-driven change, struggle to explain these shifts.
Context is everything
The same function can be generated ten different ways depending on the prompt, tools, and context windows involved. Two almost-identical diffs can have very different risk profiles.
Without lineage, you cannot explain why one path failed and another succeeded. You just see "an error" and a stack trace that hides the role AI played.
Guardrails need to move left
Most orgs still treat security and quality as "after deployment" concerns. With AI coding, that is too late.
The right place to catch hallucinations, leaks, or policy violations is while the code is being constructed, not days later in production. Guardrails need to wrap the coding process itself, not just the runtime behavior.
Conventional monitoring was not built for this world.
A Closed-Loop Model for AI Coding Observability
Observability by itself is not the goal. Dashboards do not ship better software. What you need is a closed loop that ties observability to evaluation and enforcement.
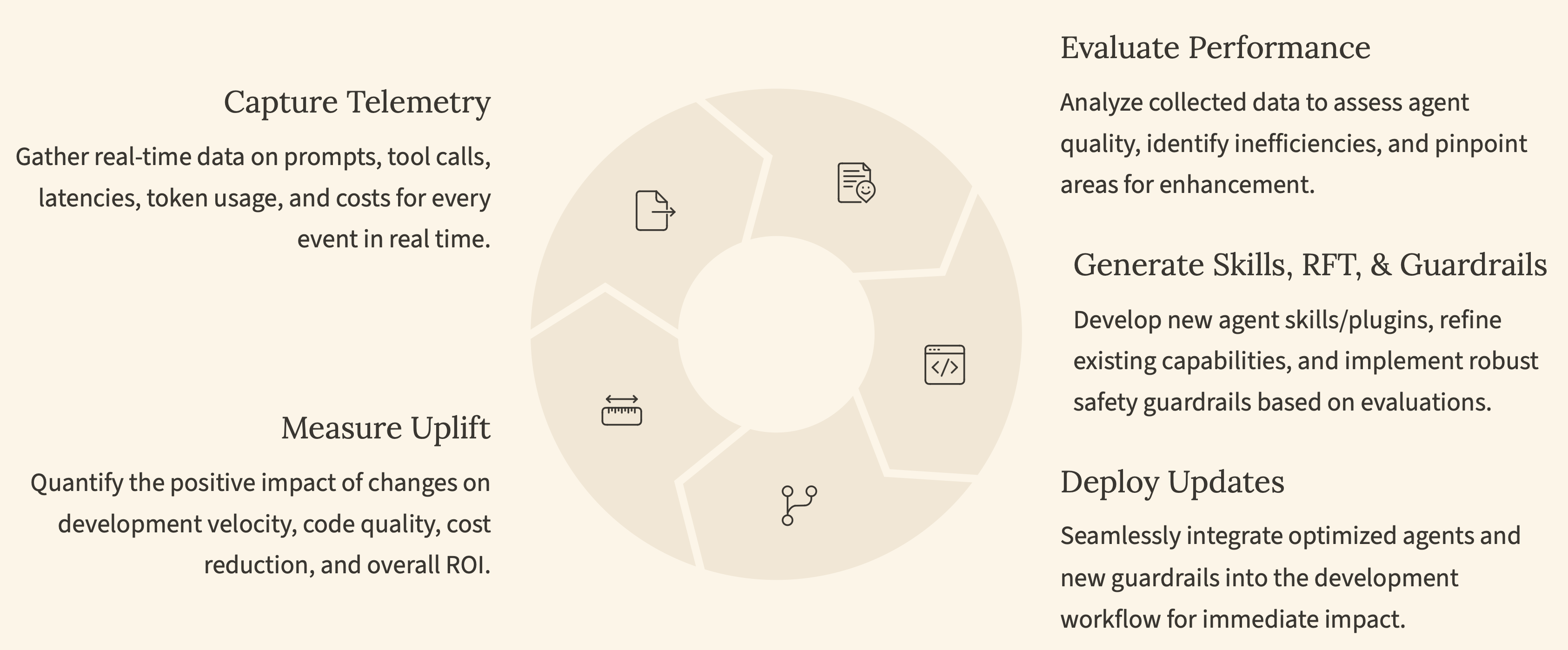
A practical model looks like this:
1. Trace
Start by capturing the full story around each AI-assisted change: prompts, tool calls, latency, tokens, and context per PR or branch. Make this structured and queryable.
Now, when someone asks "What happened here?", you have more than a diff. You have a timeline.
2. Evaluate
On top of those traces, run automated evaluations on AI-generated diffs.
Check for correctness. Look for hallucinations. Enforce schemas and contracts. Run policy checks that understand the intent and context of the code, not just the text.
Evaluations turn raw traces into judgments you can act on.
3. Guardrail
Do not let evaluations live in a dashboard only. Turn them into policies.
For example:
- Block or warn on PII or secret leakage.
- Enforce allow/deny lists for tools and external MCP servers.
- Require extra review for high-risk patterns or large, AI-generated changes
Guardrails make it harder for risky changes to slip through unnoticed.
4. Improve
Finally, close the loop.
Use this telemetry to understand where developers are getting stuck:
- Which conversations with agents end in frustration?
- Where do retries spike?
- Which flows lead to frequent rework or rollbacks
Then standardize on what works: shared skills, plugins, and agent flows tuned for your org, or fine-tuned and RAG-enhanced models specialized for tasks like code review, debugging, or refactoring.
Over time, your AI coding system does not just "run"-it learns.
Shifting Observability Left
AI coding is not "set and forget." It is adaptive, high-variance, and directly tied to developer velocity and risk.
If you treat it like a black box, you will:
- Ship slower instead of faster.
- Carry invisible security exposure.
- Struggle to prove any real ROI.
If you treat it as an observable system-with traces, evaluations, and guardrails tailored to prompts, tools, and PRs-you unlock something different:
You can trace → evaluate → guardrail → improve on a continuous loop.
You can prove velocity and quality improvements with real data, not just anecdotes. And you can make AI coding safe to scale across your organization.
When you start collecting the data that truly describes how your software is being built, you unlock the potential to autonomously improve developer productivity and free your teammates to focus on higher-impact work.
Subscribe to unlock premium content
Sed at tellus, pharetra lacus, aenean risus non nisl ultricies commodo diam aliquet arcu enim eu leo porttitor habitasse adipiscing porttitor varius ultricies facilisis viverra lacus neque.